DistributedDataParallel non-floating point dtype parameter with requires_grad=False · Issue #32018 · pytorch/pytorch · GitHub
$ 26.99 · 4.6 (503) · In stock
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re
parameters() is empty in forward when using DataParallel · Issue

Torch 2.1 compile + FSDP (mixed precision) + LlamaForCausalLM
RuntimeError: Only Tensors of floating point and complex dtype can
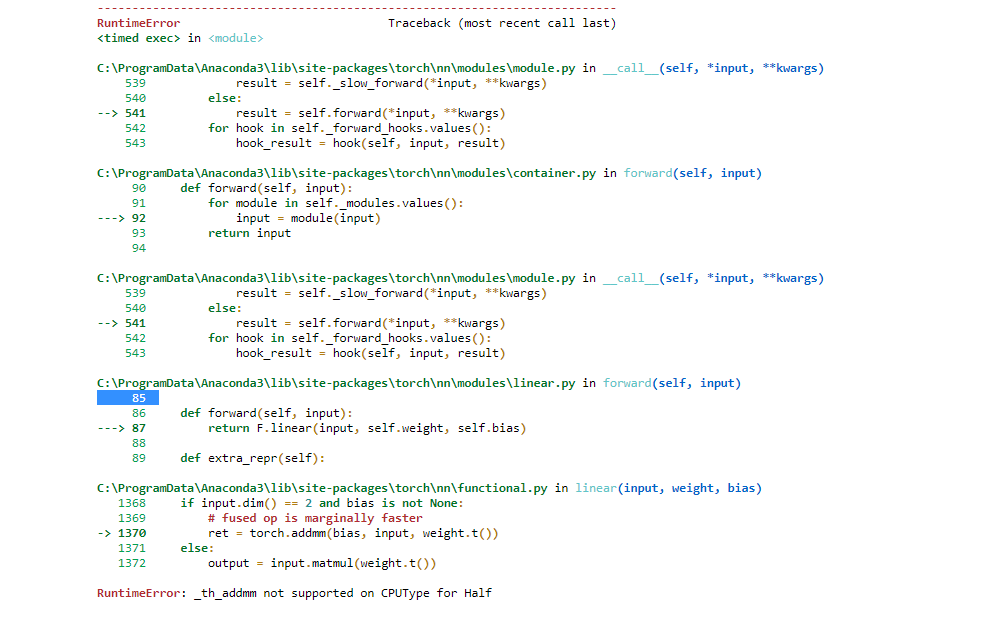
Training on 16bit floating point - PyTorch Forums

Achieving FP32 Accuracy for INT8 Inference Using Quantization

Rethinking PyTorch Fully Sharded Data Parallel (FSDP) from First

Wrong gradients when using DistributedDataParallel and autograd

Cannot convert a MPS Tensor to float64 dtype as the MPS framework
Tensor data dtype ComplexFloat not supported for NCCL process

Torch 2.1 compile + FSDP (mixed precision) + LlamaForCausalLM