How to Fine-Tune a 6 Billion Parameter LLM for Less Than $7
$ 30.00 · 4.9 (187) · In stock
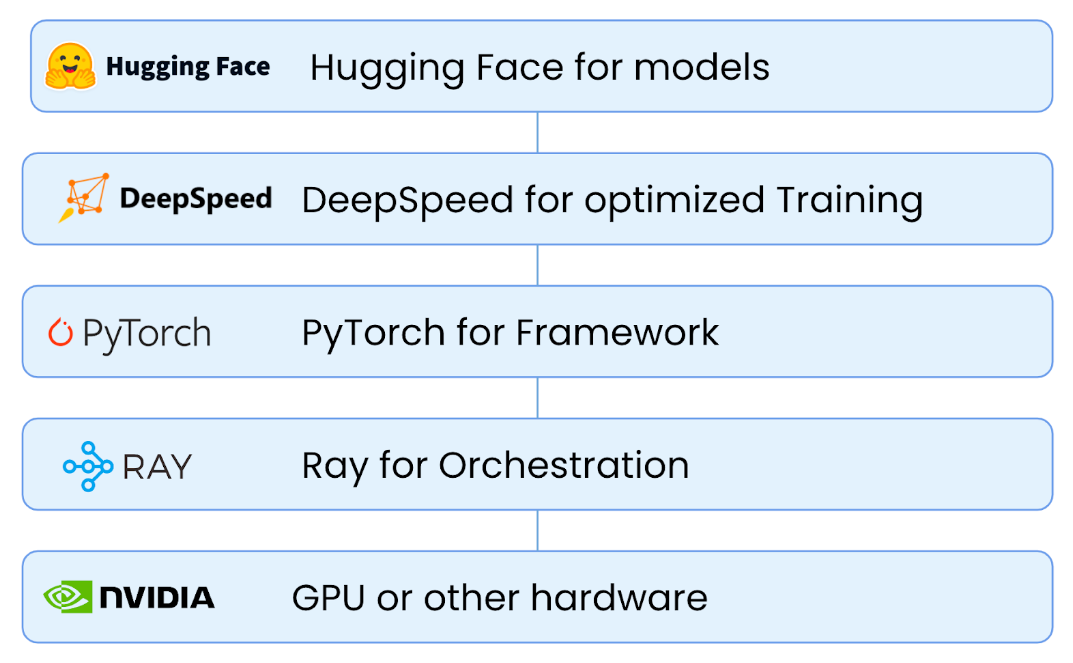
In part 4 of our Generative AI series, we share how to build a system for fine-tuning & serving LLMs in 40 minutes or less.

How Smaller LLMs Could Slash Costs of Generative AI
Fine-tuning methods of Large Language models
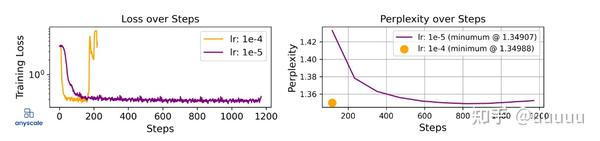
大模型LLM微调的碎碎念- 知乎
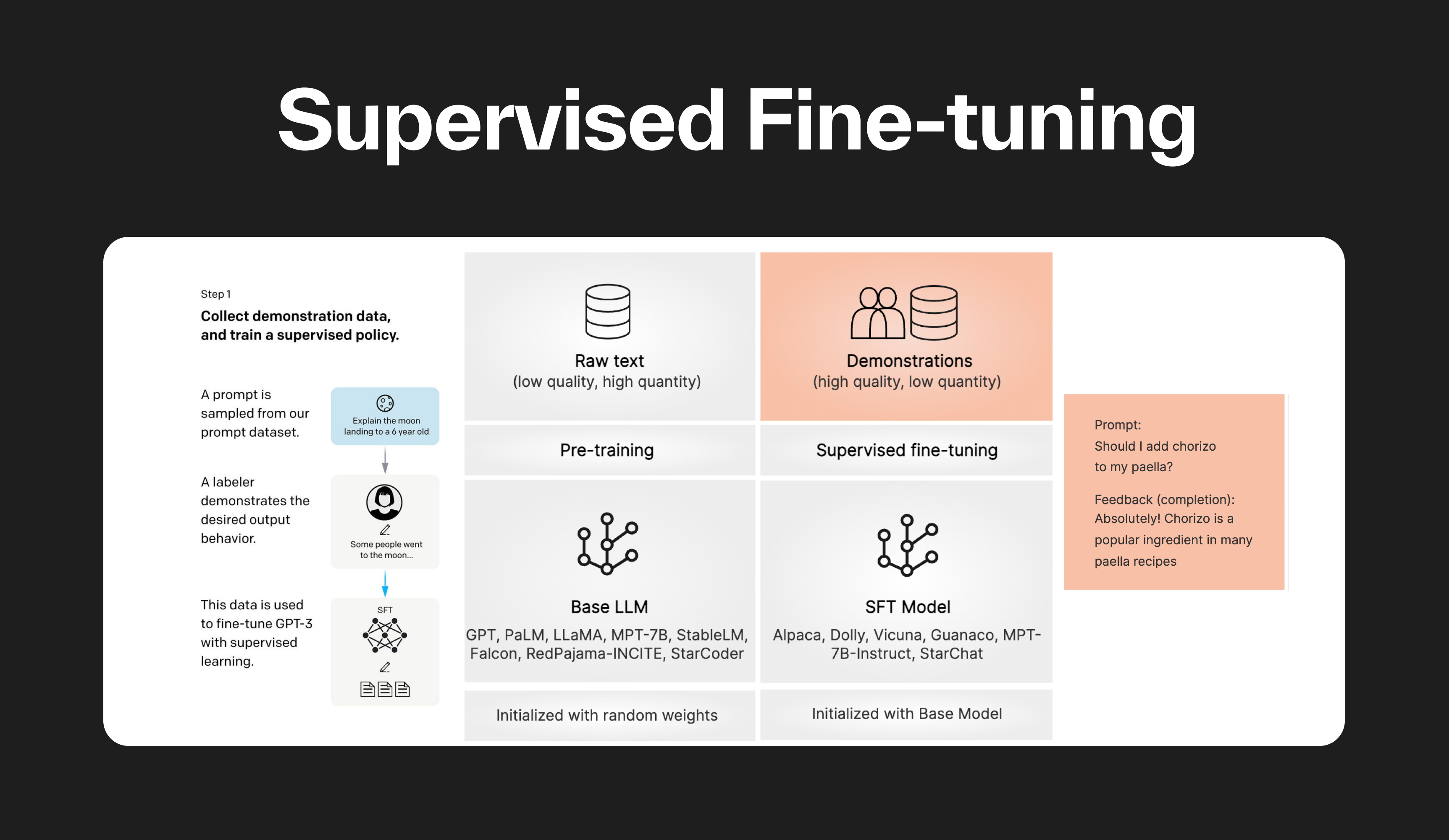
What is supervised fine-tuning? — Klu
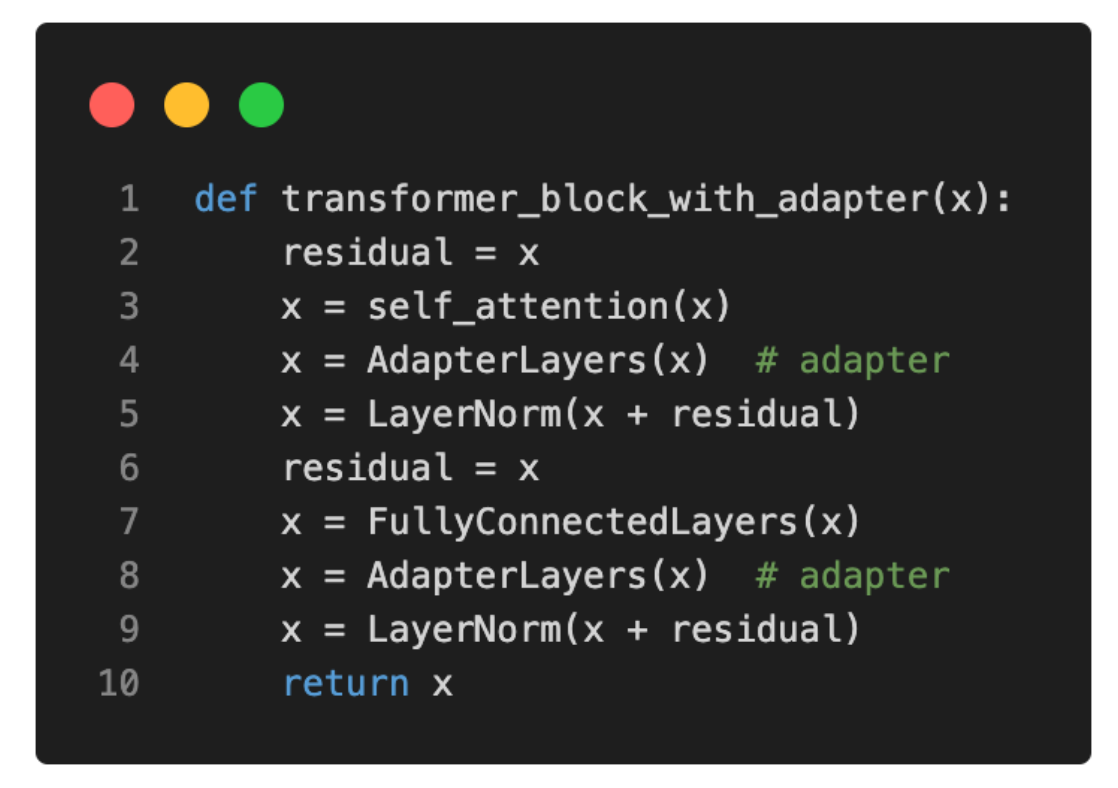
Understanding Parameter-Efficient Finetuning of Large Language Models: From Prefix Tuning to LLaMA-Adapters
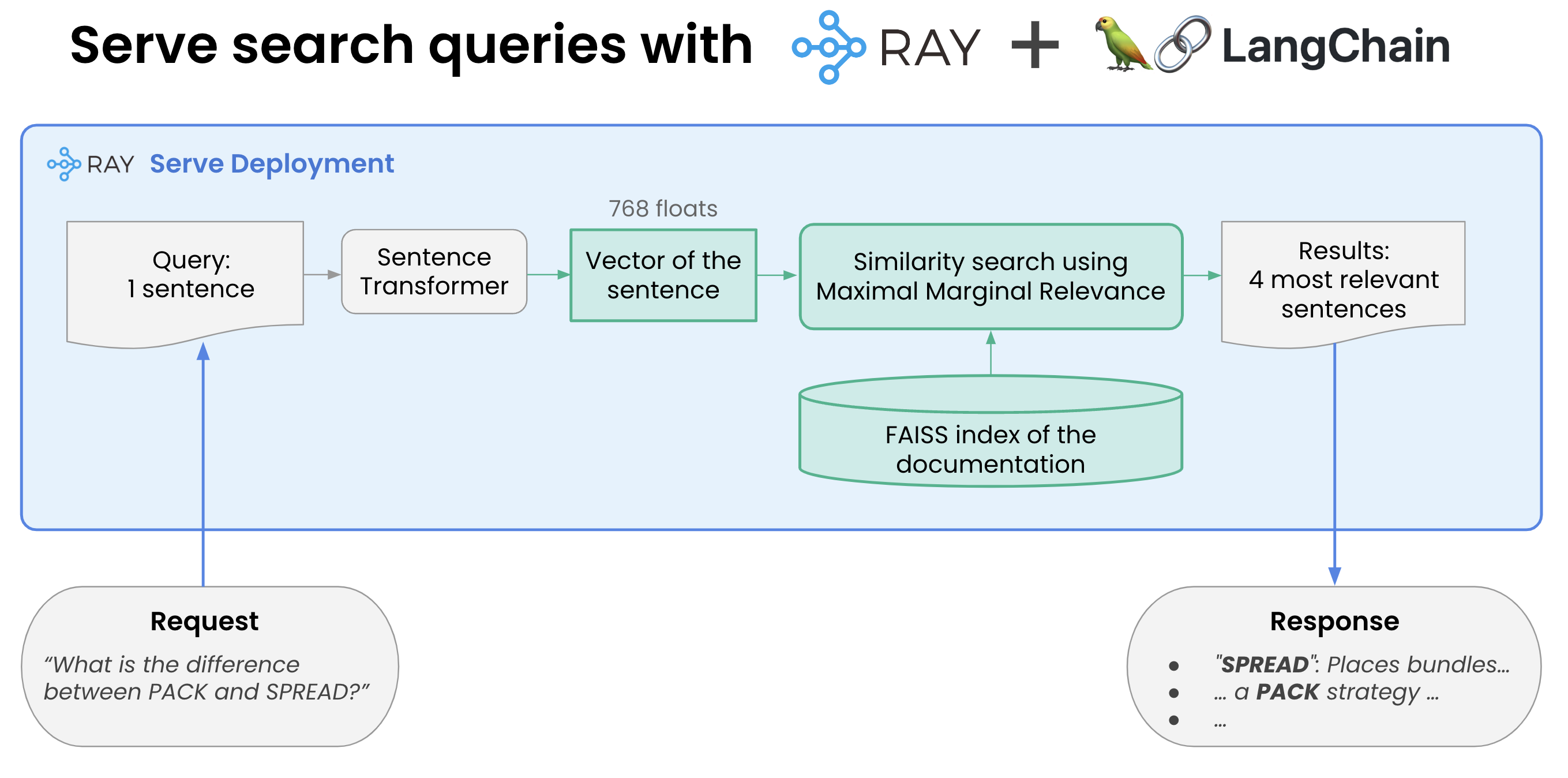
LLMs:《如何使用Ray + DeepSpeed + HuggingFace简单、快速、经济有效

What is low-rank adaptation (LoRA)? - TechTalks

Jo Kristian Bergum on LinkedIn: The Mother of all Embedding Models

3 Easy Methods For Improving Your Large Language Model
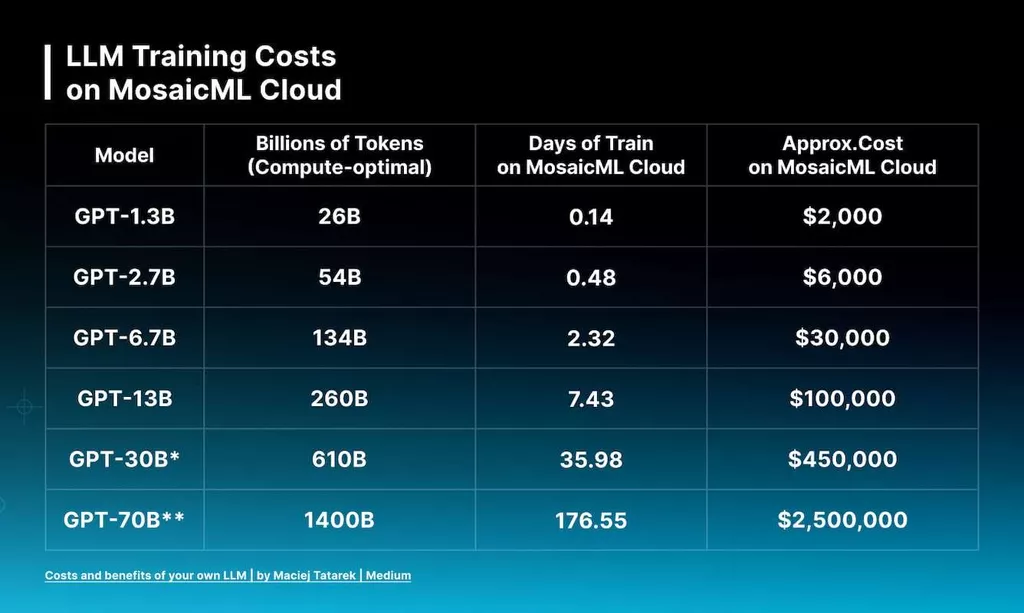
Fine Tuning Large Language Models: A Complete Guide to Building an LLM
R] ChatGLM-6B - an open source 6.2 billion parameter Eng/Chinese bilingual LLM trained on 1T tokens, supplemented by supervised fine-tuning, feedback bootstrap, and RLHF. Runs on consumer grade GPUs : r/MachineLearning

A High-level Overview of Large Language Models - Borealis AI

Top Large Language Models (LLMs): GPT-4, LLaMA 2, Mistral 7B, ChatGPT, and More - Vectara
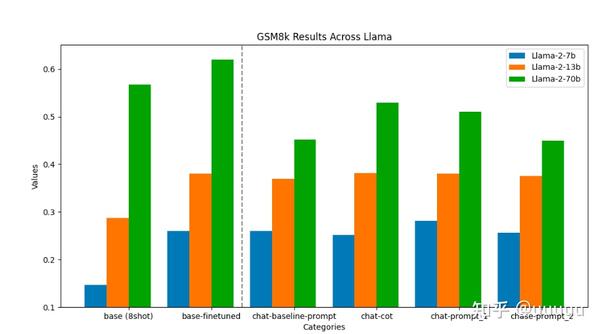
大模型LLM微调的碎碎念- 知乎

Eric Loncle on LinkedIn: Some IA video for the Fun.